


In this blog, we answer frequently asked questions about SDTM – from its purpose, to SDTM dataset creation, and everything in between.
Let’s start with the basics.
What is SDTM in clinical trials?
The Study Data Tabulation Model (SDTM) is one of the most important CDISC data standards. It's a model (or framework) used for organizing data collected in human clinical trials. The model was developed by CDISC – the Clinical Data Interchange Standards Consortium – an organization that develops standards for use when collecting, processing and submitting medical research data.
It is mandatory for organizations to use the SDTM standard when submitting clinical data to the US Food and Drug Administration (FDA), the UK Medicines and Healthcare products Regulatory Agency (MHRA), and the Pharmaceuticals and Medical Devices Agency (PMDA) in Japan.
The SDTM standard explains exactly how to organize and present the data, for easier analysis and reporting by the regulator. There are benefits for organizations too: studies are more consistent, because they’re all in the same standard format. This enables easier data sharing and reuse. We talk more about the benefits of SDTM a little later in this blog.
Why is SDTM important?
SDTM is there to give regulatory reviewers a clear description of the structure, attributes, and contents of each dataset, and the variables submitted as part of your clinical trial. Before CDISC SDTM was enforced, different studies used different domain names for each domain, as well as different variables, and different variable names. There was no industry-wide standardization in place.
As a result, reviewers spent huge amounts of time trying to get the data into a standard format – figuring out the domain names and names of the variables in each dataset – rather than reviewing the data itself. This ultimately prolonged the clinical trial process.
The introduction of CDISC SDTM
CDISC SDTM allows data collection to be standardized end-to-end. Now we have:
- Standard domain names
- A standard structure for each domain
- Standard variables
- Standard names for SDTM datasets
This means that every bit of data collected in every study can now be easily identified. Regulators can review the data much quicker, making the process far more efficient.
Find out what other CDISC standards are required for regulatory submissions.
|
Formalizing the structure of domains has also led to the development of conformance rules, by both the CDISC SDTM team and regulatory bodies. These rules are programmed into software validation tools to automate the checking of SDTM clinical datasets against the conformance rule. |
What is the latest version of SDTM?
CDISC build the SDTM standards from two important models:
- ‘Core’ Study Data Tabulation Model
- Latest version - SDTM v2.0
- The core model provides a standardized set of variables, assembled into ‘classes’, which are refined and built into variable collections for specific uses cases (SDTM-IG domains). Examples of these include, Vital Signs observations, Adverse Events, and Medical History reporting. The SDTM core model also supports the non-human trial standard SEND-IG.
- SDTM Implementation Guide (SDTM-IG)
- Latest version - SDTM implementation guide v3.4
CDISC is always developing new domains. It’s important to regularly check the CDISC website for the latest updates. Read more about planned updates to standards.
What is the SDTM implementation guide?
The SDTM Implementation Guide (SDTMIG) is a very important document, so let’s go into a bit more detail on what’s contained within it.
According to CDISC: “Where the SDTM provides a standard model for organizing and formatting data for human and animal studies, the SDTMIG is intended to guide the organization, structure, and format of standard clinical trial tabulation datasets.”
The SDTMIG is an essential resource to help you map or convert data to SDTM. We would highly recommend familiarizing yourself with this before attempting to do either SDTM mappings or conversions.
What are SDTM datasets?
The term ‘SDTM datasets’ refers to the data tables that are created in alignment with the SDTM standard, for submission to regulatory authorities. The datasets include details about clinical study participants, including visits, treatments, and observations.
Below is an example of an SDTM+ dataset for DM (Demographics) domain.
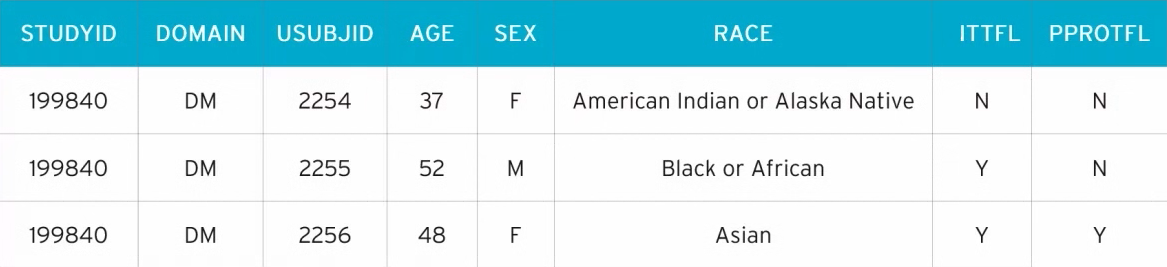
What are SDTM domains?
In order to be able to correctly implement SDTM, it’s important to have a good understanding of its domains and how they’re structured.
According to CDISC, SDTM domains are ‘A collection of logically related observations with a common, specific topic that are normally collected for all subjects in a clinical investigation. NOTE: The logic of the relationship may pertain to the scientific subject matter of the data or to its role in the trial.’
How many SDTM domains are there?
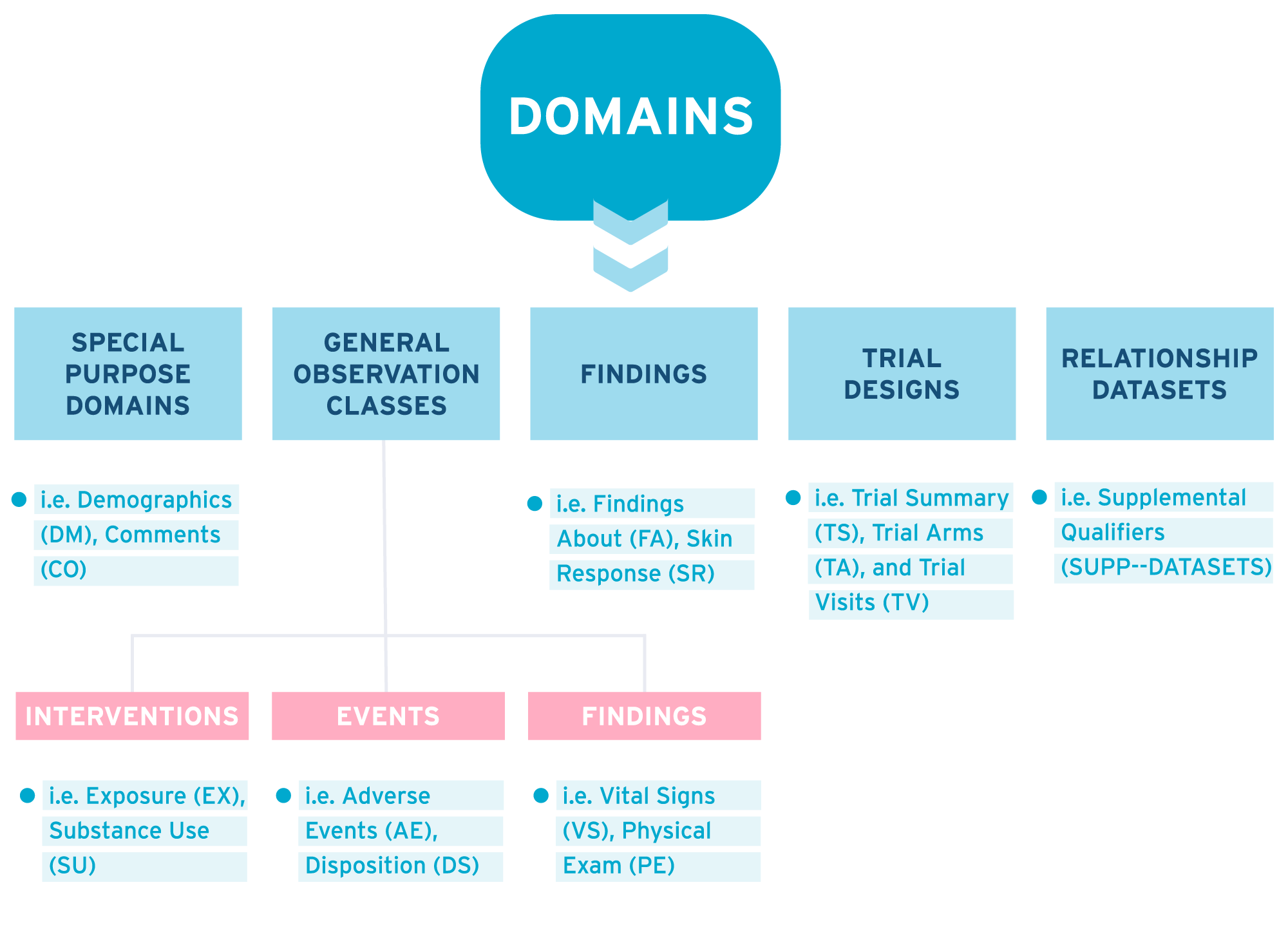
SDTM domains are divided into the following classes:
- Special purpose domains
- General observation classes
- Findings about
- Trial designs
- Relationship datasets
We’ll talk first about the general observation classes.
General observation classes
SDTM is based on the observations that are collected from subjects taking part in a clinical trial. An observation is a piece of data collected during a study. For example, “Subject 12 had a mild headache starting on study day 5”.
Most observations collected should be classified into one of the general observations classes (also known as data classes). The general observation classes are:
- Interventions datasets capture treatments and procedures that are given to a subject as specified by the protocol. Examples are Exposure (EX), Concomitant Medications (CM), and Substance Use (SU), e.g. tobacco, caffeine, and alcohol.
- Events datasets capture planned protocol milestones such as randomization and study completion. Unplanned incidents that occur before, or during a study are also captured. Examples are Adverse Events (AE), Disposition (DS), and Medical History (MH).
- Findings capture observations that address specific questions such as observations made during physical examinations, laboratory tests, ECG testing, etc. Findings About is included and captures data related to the Interventions and Events classes. Examples are Vital Signs (VS), Physical Exam (PE), Labs (LB), and Subject Characteristics (SC).
- Findings about Events and Interventions capture more details about e.g. an Adverse Event.
The general classes provide a framework for classifying data not covered by a specific domain. The sub-categories provide a more refined collection of variables for custom domains.
What is a domain in SDTM?
A domain is simply a group of observations that share a common topic, such as Medical History or Vital Signs. Currently, there’s a large collection of domains within the classes, and CDISC is constantly developing more. Each domain consists of a name and an associated abbreviation. For example, here's a list of SDTM domains:
- Demographics (DM)
- Subject Visits (SV)
- Adverse Events (AE)
- Lab Results (LB)
- Vital Signs (VS)
In addition to the ‘General observation classes’, there are the four special case classes:
- Special purpose domain datasets can be Demographics (DM), Comments (CO), Subject Elements (SE), and Subject Visits (SV).
- Trial designs has datasets that describe the design of a trial. Examples are Trial Summary (TS), Trial Arms (TA), and Trial Visits (TV).
- Relationship datasets represent the relationships between datasets and records.
- Study Reference datasets that provide structures for representing study-specific terminology used in subject data. Examples include Device Identifiers (DI) and Non-host Organism Identifiers (OI).
Each SDTM domain usually consists of a file, named after the domain (e.g AE.xpt).
What about safety domains in SDTM?
Safety domains in SDTM include information about the safety of study participants, such as any medicines they took and any adverse events that occured.
What are SDTM variable roles?
Domains are prefixed by a two-character domain code that’s used to map a variable to a domain. For example, the domain Medical History is prefixed by the domain code MH. The variable –SEQ (sequence number) contains two hyphens that indicate a domain code is required. So, the example becomes MHSEQ.
Another example is the variable –TESTCD (test code) in the Vital Signs (VS) domain becomes VSTESTCD. Each domain has a dataset which is a collection of related data. SDTM datasets are described by a set of named variables. And each of these named variables is categorized by their role.
A role category conveys a particular type of information about a variable. Variables can have just one role.
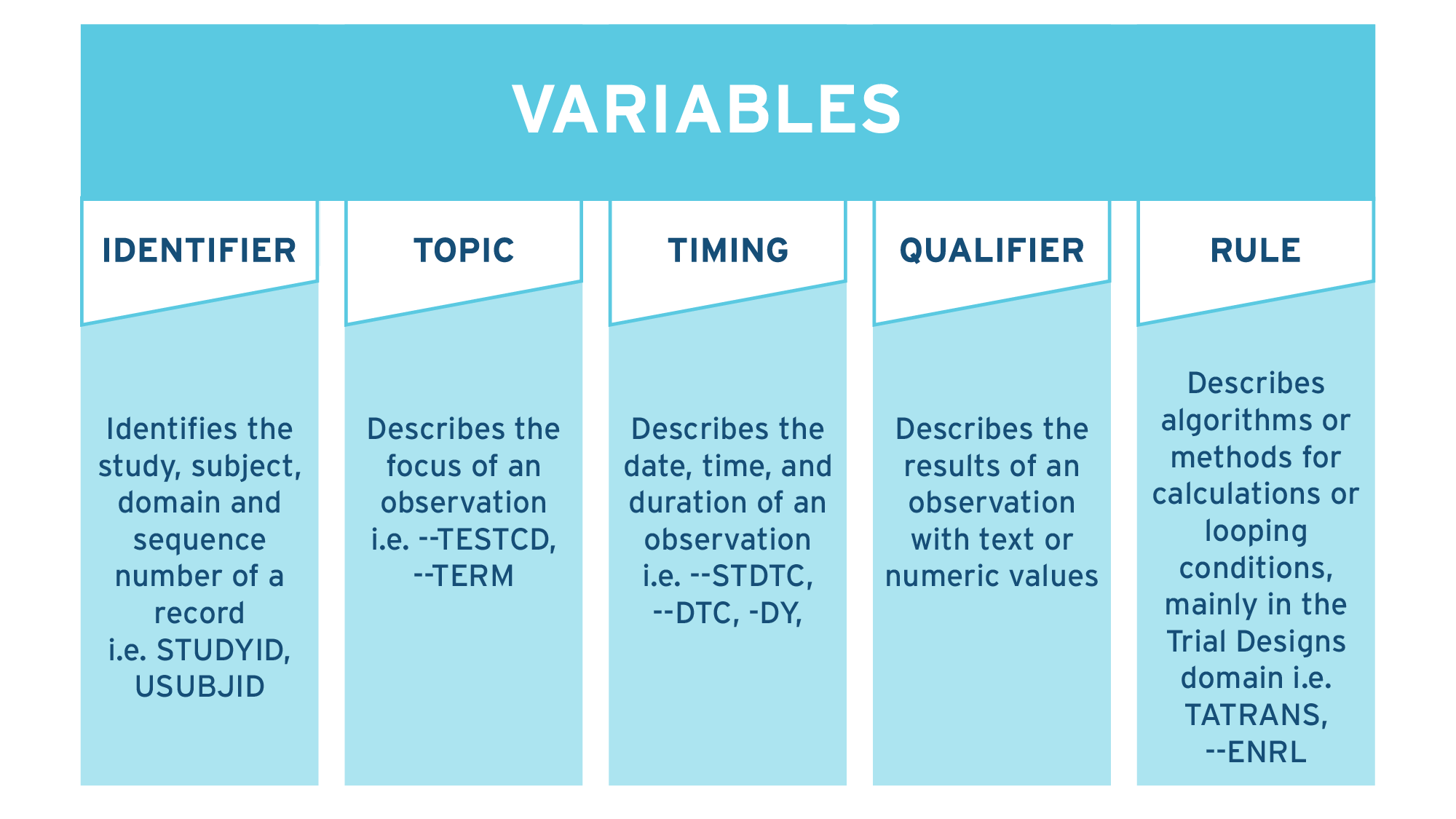
Variable roles have five categories
- Identifier variables allow the study, subject, domain and sequence number of a record to be identified.
- Topic variables describe the focus of an observation.
- Timing variables describe the date, time, and duration of an observation.
- Qualifier variables describe the results of an observation with text or numeric values.
- Rule variables describe algorithms or methods for calculations or looping conditions and are mainly used for the Trial Design domain.
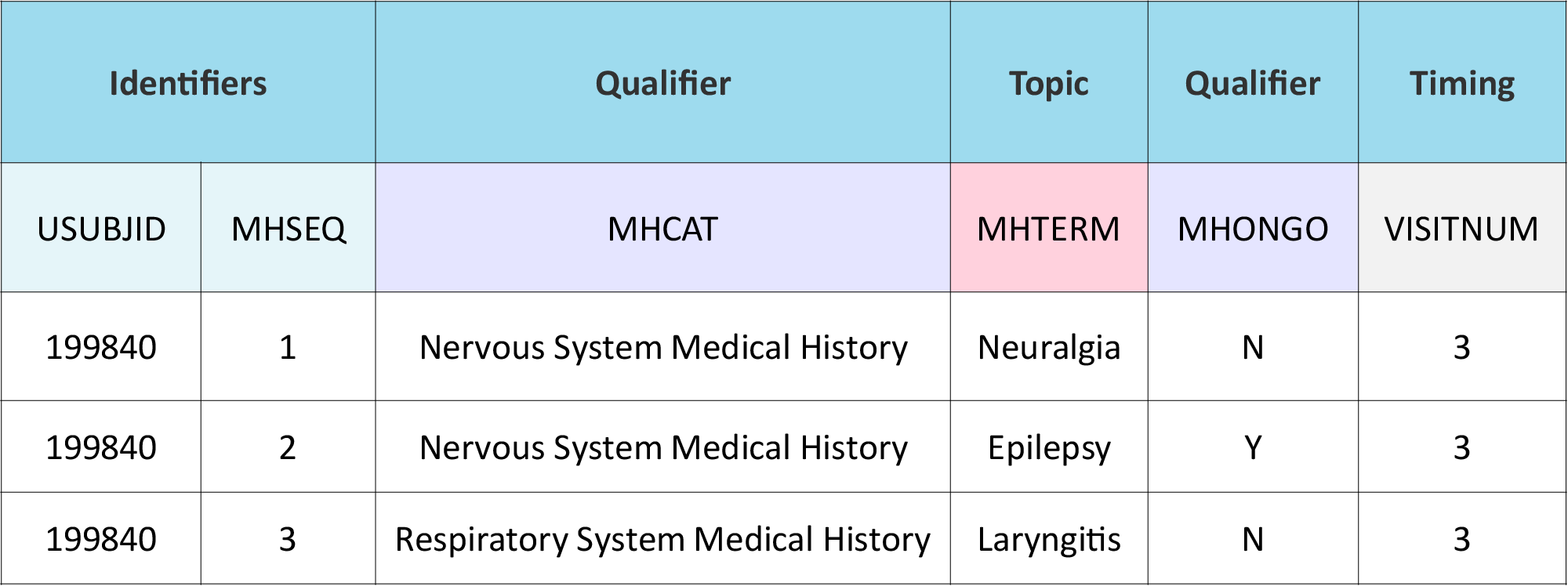
In the example below, variable roles are shown in the top row of the table. The color-coded areas on the second row show the variables that correspond to the variable roles.
Qualifier variables are further categorized as follows:
- Grouping qualifiers group observations together.
- Result qualifiers describe the result for a finding.
- Synonym qualifiers contain another name for the observation.
- Record qualifiers define the supplementary attributes of an observation.
- Variable qualifiers describe the value of an observation.
What are SDTM core variables?
Core variables are a measure of compliance with the specific SDTM-IG domain model. The value of a core variable shows the importance of the variable to the overall domain structure.
Variables are divided into 3 categories:
- Required variables are needed to identify a data record, e.g STUDYID, and USUBJID. Or, they are needed to make a record easily understood, e.g TERM and TEST. They must always be included in the dataset and cannot be null.
- Expected variables are needed to make a record useful within a specific domain. They must always be included in the dataset but they can be null for some records. If no data is collected, a comment must be included to explain why.
- Permissible variables must be included in the dataset if results are collected or derived, but they can be left null or blank.
Variables from the parent class can also be inserted into the domain if required.

SDTM dataset creation and SDTM mapping
So how do you implement SDTM?
The following section explains how to map source datasets to SDTM domains, as well as important considerations, and other necessary deliverables needed for SDTM dataset creation.
What is SDTM mapping?
The SDTMIG extends and refines the SDTM core model with specific domain implementations, business rules, assumptions, and examples. It should be used along with the relevant version of SDTM. So, make sure you have the correct versions of both of these documents (we referred to these above).
How do you create SDTM datasets?
Here are some basic steps to help keep you on the right track with your SDTM dataset creation:
- Determine which SDTM domains to create.
- Compare the SDTM data to the SDTM metadata and map directly where possible.
- Map the rest of the source datasets to SDTM domains.
- Map variables in the source datasets to the variables in the SDTM domains.
- Decide whether custom domains and SUPPQUAL domains need to be created.
- Perform the data conversion – there are various mapping tools you can use to do this.
- Validate the SDTM datasets.
- Generate and validate Define.xml.
Different types of SDTM mappings
There are a number of different types of SDTM mappings you can do for steps 2, 3, and 4 above.
- Directly map to a domain variable without making any changes.
- Rename the source variable name and label without the need to make any other changes.
- Map values to standard units or terminology.
- Change the format of a source variable.
- Combine two or more source variables to make a single domain variable.
- Split a single source variable into two or more domain variables.
- Derive a domain variable from one or more source variables using logic, computation, algorithm or decoding.
What is an SDTM mapping specification document?
SDTM mapping can be a complicated task, so it’s important to plan everything out in advance. By creating a mapping specification, you’ll know where data came from, how it got there, and where it’s to go to.
The SDTM mapping specification is an important document that’s used when designing the process by which raw data will be converted to SDTM. This document specifies how the raw data is to be converted, and is used by the SDTM programmer and testing team.
How do you create an SDTM mapping specification document?
- Examine the CRFs and raw data and identify which SDTM domains you need.
- Against each SDTM domain, note which raw dataset will provide the input data.
- Against each SDTM domain, list all variables and describe how they are to be programmed.

There are various mapping scenarios you can use – check out our best practice guide to SDTM mapping for more information.
It’s important to use the SDTM model and Implementation Guide during the SDTM mapping process. And by using standard process and tools, you’ll maximize your chances of success.
SDTM mapping specifications should be developed at the same time as annotating case report forms (CRFs). The mapping specification tells the user how to do a mapping. An annotated CRF is a visual representation of a mapping showing how the source data relates to the SDTM data.
What are SDTM annotated CRFs?
As part of your submission to the FDA, you must provide a blank CRF. The file should be called blankcrf.pdf. Each question on the form must be manually annotated to show the origin of variables. It links the fields on the form with the variables in the dataset (the source of the data). Annotations help the reviewer find where variables come from in the submitted SDTM datasets.
Below, you can see an example of an annotated CRF within ryze, our clinical metadata repository. Find out more about the benefits of automating annotated CRFs.
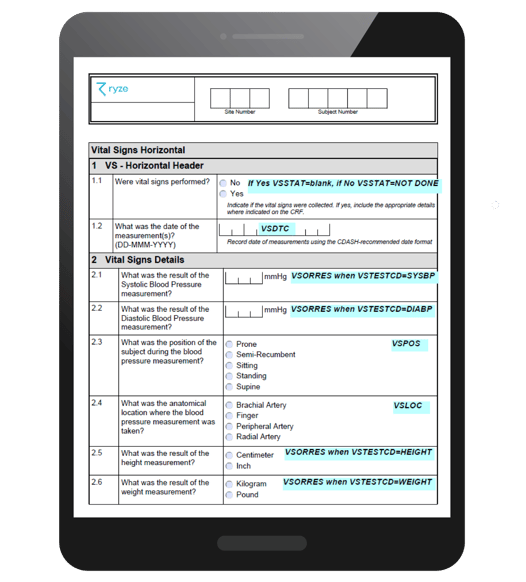
What is SDTM controlled terminology?
SDTM has standard code lists for particular variables, containing allowable values for these variables. These allowable values should be used in submissions to the regulator, so ensure the SDTM datasets are CDISC compliant. You should always use the most up to date version of controlled terminology when you start to map your SDTM datasets. Find out more about using NCI controlled terminology for standardizing data.
CDISC and NCI Enterprise Vocabulary Services partnered up to develop a standard controlled terminology. However, the CDISC / NCI controlled terms for Lab tests are not unique. They require additional information for differentiation.
Other medical dictionaries can be used, such as MedDRA and WHOdrug.
What are LOINC codes?
Over the last 25 years, the LOINC project has provided a standard classification for health measurements. Most SDTM programmers will encounter ‘LOINC Code’ information in Lab data. But the classification system has been extended to cover other measurements such as ECG. So, what is LOINC? LOINC is an internationally recognized classification system which is often requested in regulatory data submissions to provide context to clinical measurement data, such as Labs and ECG.
Read more about LOINC codes and SDTM.
What is the SDTM Define-XML standard?
The FDA requires a Define.xml file to be included for all drug submissions. The latest version of the standard is Define 2.1. It describes the content and structure of data collected during the study which are domains, variables, methods, controlled terminology, and supporting documents. The Define.xml file makes the review of study data quicker and easier for the FDA.
For more information about Define-XML, you can read our blog about using the Define XML standard for dataset design, or download our free guide to the 6 dos and don’ts of Define-XML.
 Creating a define.xml requires a lot of programming expertise. It takes a lot of time. That’s why it’s so important to make the process as quick and easy as possible.
Creating a define.xml requires a lot of programming expertise. It takes a lot of time. That’s why it’s so important to make the process as quick and easy as possible.
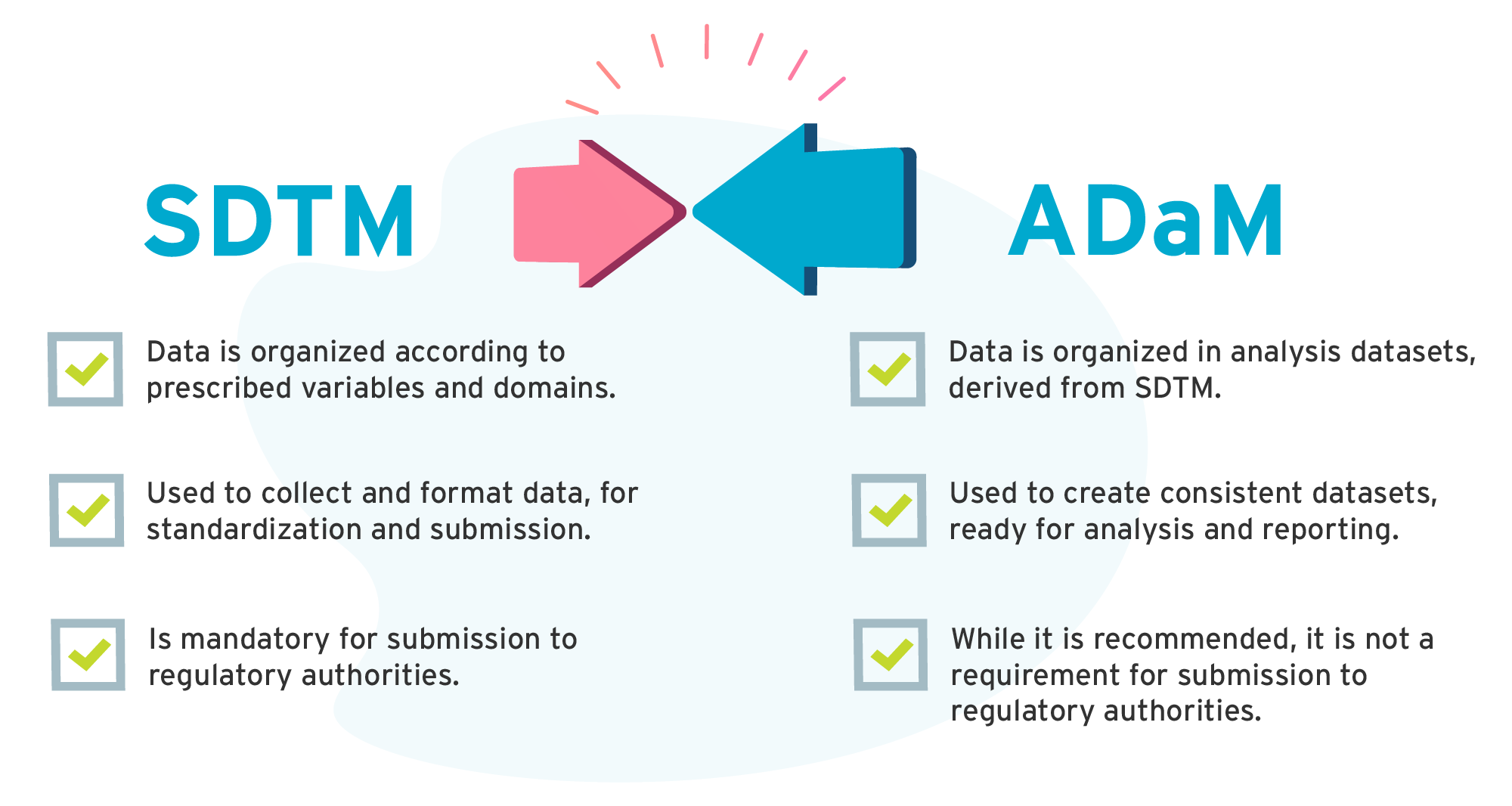
What is the difference between ADaM and SDTM?
Another important CDISC standard is the Analysis Data Model, or ADaM. ADaM relates to the creation of analysis datasets and associated metadata. The standard allows you to generate figures, listings, and tables more easily, and also ensures traceability. This means that reviewers are able to assess and approve a submission more quickly. ADaM is a little different to SDTM. It’s less strict, but like SDTM it has a core model and an implementation guide.
The main differences between ADaM and SDTM:
What is the difference between CDASH and SDTM?
While SDTM is about organizing and formatting your data ready for submission, the purpose of the Clinical Data Acquisition Standards for Clinical Research (CDASH) is to harmonize your data collection with your SDTM submission.
What is the difference between SDTM and SEND?
The Standard for Exchange of Nonclinical Data (SEND) defines standardized domains for non-clinical trial data, whereas SDTM is concerned with the organization and formatting clinical trial data.
What are the benefits of using SDTM in clinical trials?
There are many benefits of implementing SDTM in your clinical trials, including:
- Consistency across studies - with standards in place you don’t need to reformat your data to use in different systems or different studies
- Improved data quality and fewer errors, because studies are created in accordance with agreed standards
- Metadata reuse (such as case report forms, terminologies, datasets) means less time and effort spent on each study
- Faster, easier internal reviews
- More efficient process for acquisition, aggregation, analysis and reporting
And if your data standards are implemented correctly, you can be confident knowing that your study complies with the FDA when the time comes for submission.
Ready to implement SDTM?
There’s a lot to get your head around with SDTM. But don’t worry – we can help!
We were one of the first ever CDISC members over 18 years ago, and today we’re active members of the CDISC XML Technology team.
We’ve used this knowledge and experience to write a guide to the 5 most common SDTM implementation challenges we see, and more importantly – how to solve them.
So, if you’re ready to start implementing SDTM, why not download the guide to read about managing the SDTM standard, SDTM in EDC build, and retrospective mapping.

Author's note: this blog post was originally published in July 2020 and has been updated for accuracy and comprehensiveness.
![]()
About the author

Ed Chappell
Solutions Consultant | Formedix
Ed Chappell has been working as a Solutions Consultant with Formedix for over 15 years, and has 22 years’ experience in data programming. He authored and presents our training courses for SEND, SDTM, Define-XML, ODM-XML, Define-XML and Dataset-XML.
Ed was heavily involved in the development of our ryze dataset mapper, and works closely with customers on SDTM dataset mapping. As an expert in clinical data programming, Ed also supports customers with Interim Analysis (IA) SDTM and FDA SDTM clinical trial submissions.


