One of the most important standards when it comes to clinical trial submission is the Analysis Data Model (ADaM). ADaM standards outline how to create analysis datasets and associated metadata. This allows a statistical programmer to generate figures, listings, and tables more easily and ensures traceability, which means that reviewers are able to assess and approve a submission more quickly.
Developed as part of the wider family of CDISC standards, ADaM applies a set of five fundamental principles. Analysis datasets and their associated metadata must:
- facilitate clear and unambiguous communication
- provide traceability between the analysis data and its source data (SDTM)
- be readily usable by common software tools
- be accompanied by metadata
- be analysis-ready
We dug a little deeper and found that three key things are crucial to understanding and implementing ADaM standards.
1. ADaM goes hand in hand with SDTM
The first thing to know is that while they might have different functions, ADaM and SDTM are closely tied together.
Before we look at how they work together, let’s first look at what makes them different.
SDTM (Study Data Tabulation Model)
CDISC SDTM is the name of the model (or framework) used for organizing data collected in human and animal clinical trials. SDTM is there to give regulatory reviewers – namely the FDA – a clear description of the structure, attributes, and contents of each dataset, and the variables submitted as part of your clinical trial. Find out all you need to know about SDTM or download our free guide on how to overcome SDTM implementation problems.

ADaM (Analysis Data Model)
CDISC’s ADaM is a bit different to SDTM. It still has a core model and an implementation guide, but the model is not as prescriptive. Additional variables can be added within certain constraints defined by the model. This gives it the flexibility to be used for any type of analysis while providing a level of standardization that allows it to be easily understood by reviewers.
So, how do they work together? While SDTM is used to create and map collected data from raw sources, ADaM is all about creating data that’s ready for analysis. ADaM datasets should ALWAYS be derived from SDTM. It could be the domain, it could be a supplemental qualifier, but the source is always the SDTM datasets.
ADaM datasets example
SDTM datasets are grouped to ease visual review. For example, a reviewer could filter a vital signs dataset for body temperature for a subject across the entire trial and spot any patterns or anomalies.
ADaM datasets are organised for a different purpose. ADaM is the arrangement of variables so that you can easily perform a calculation for a specific result presented in the Table, Listings and Figure (TLF). It may be something as simple as providing a breakdown of the number of male and female subjects in the study and which age groups they fall into. To achieve that, you need to bring together all the required variables from the SDTM sources, and rearrange them into a different grouping to get your result.
Because SDTM data is a standardized structure, standardized programs can be used to derive ADaM data, leading to increased efficiencies. For example, if you need a value from your vital signs dataset, such as the vital signs start date, you can import it from SDTM directly into ADaM. You don’t need to reinvent the wheel, and this ensures you have traceability back to the source data.
Some columns in ADaM are derived or calculated from assigned values. However, all of the general data points must come from SDTM. Take dates, for example. In SDTM, just the date would be recorded. In ADaM, you’ll have the date, its numeric version, and the analysis date which is derived from the original date. But that single date must be able to trace back to an SDTM variable, which in turn traces back to a CRF/EDC variable. This is important because it allows the FDA reviewer to see not just the analysis dataset, but also to trace exactly where the data has come from.
Read our thorough Guide to CDISC Standards Used in the Clinical Research Process.
2. Traceability is key
The second thing we found is that traceability is one of the most important aspects of the ADaM dataset. According to CDISC, traceability is “the property in ADaM that permits the user of an analysis dataset to understand the data’s lineage and/or the relationship between an element and its predecessor, the SDTM column. You should provide details of any derivations so that the FDA review can examine the maths.[…] Traceability is built by clearly establishing the path between an element and its immediate predecessor. The full path is traced by going from one element to its predecessors, then on to their predecessors, and so on, back to the SDTM datasets, and ultimately to the data collection instrument.”
Traceability facilitates transparency, which is an essential component in building confidence in the data itself. Ultimately, traceability in ADaM means a better understanding of the relationship between the analysis results, the analysis datasets, and the SDTM domains.
|
The CDISC Clinical Data Acquisition Standards Harmonization (CDASH) standard is consistent with SDTM and therefore assists in ensuring end-to-end traceability. Applying CDASH to eCRFs also makes it easier to align the CRF variables to SDTM. |
Based on the metadata and the content of the analysis dataset, the reviewer can trace how the primary and secondary efficacy analysis values were derived from the SDTM data for each subject.
3. Subject-Level Analysis Datasets are important
Finally, there is the importance of the Subject-Level Analysis Dataset (ADSL). Regulatory agency staff have stated that the ADSL is very helpful in the review of a clinical trial. According to ADaM guidelines, ADSL and its related metadata are required in any CDISC-based submission of data from a clinical trial even if no other analysis datasets are submitted.”
ADSL is used to provide the variables that describe the attributes of a subject. The structure of the Subject-Level Analysis Dataset (ADSL) is one record per subject, regardless of the type of clinical trial design. This structure allows simple merging with any other dataset, including SDTM and analysis datasets.
ADSL columns can be imported into other ADaM domains. A quirk of the standard is that it lets you combine ADSL with all the other ADaM domains. This is a bit of a shortcut; the alternative would be to combine demographics records with the adverse events column, but you already do that when you create the ADSL. It’s a bit odd in terms of traceability in that it creates two levels: one back to the ADSL and one to the SDTM domain.
You may find it helpful to visit the PHUSE Advance Hub knowledge base for more information about ADaM, including implementation and submission FAQs.
ADaM datasets are essential in your submission for drugs and product approval. And if you don’t get datasets done early on, it can cause delays in future. You even risk not collecting the exact data that’s needed for trial building.
ryze, the only all-in-one, cloud based clinical metadata repository can help you to create ADaM datasets, fast.
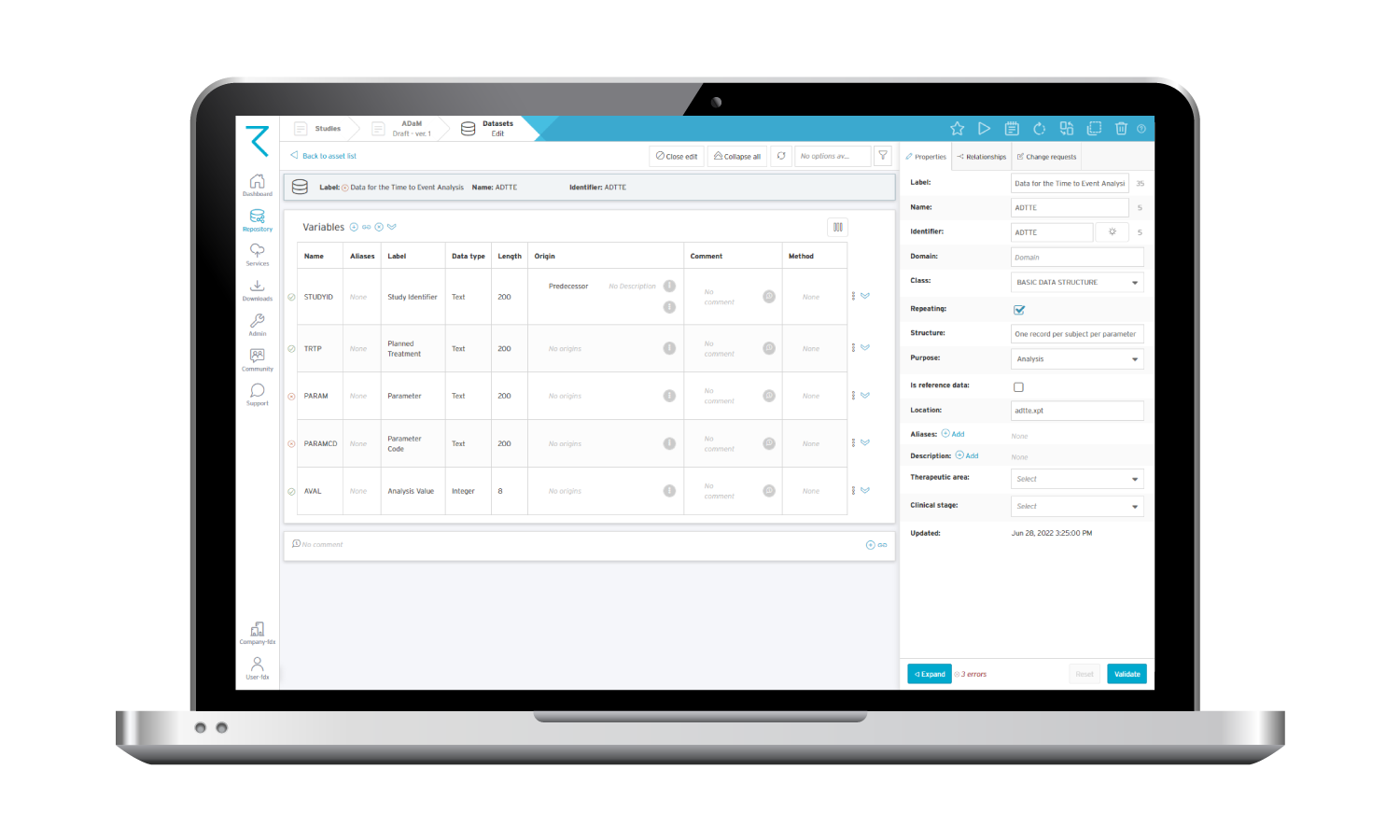
Here’s an example of how an ADaM dataset looks in ryze:
Need help building your SDTM datasets?
Why not download our free guide on how to overcome SDTM implementation problems?

Author's note: this blog post was originally published in April 2020 and has been updated for accuracy and comprehensiveness.
![]()
About the author

Ed Chappell
Solutions Consultant | Formedix
Ed Chappell has been working as a Solutions Consultant with Formedix for over 15 years, and has 22 years’ experience in data programming. He authored and presents our training courses for SEND, SDTM, Define-XML, ODM-XML, Define-XML and Dataset-XML.
Ed was heavily involved in the development of our ryze dataset mapper, and works closely with customers on SDTM dataset mapping. As an expert in clinical data programming, Ed also supports customers with Interim Analysis (IA) SDTM and FDA SDTM clinical trial submissions.