
Tags:
SDTM

SDTM mapping can be one of the most challenging programming problems in a clinical trial build. It involves mapping datasets from a non-CDISC structure, for example the structure used in your clinical data management system, to the CDISC SDTM structure, as required by CDISC standards.
These standards were put in place to make it easier for a regulator to understand and process clinical trial data, and they must be adhered to. Best practice is always to align with CDISC standards before you collect any patient data.
|
If CDISC standards haven’t been implemented from the start, it’s going to take a lot more time and effort when it comes to SDTM mapping later on. Read our guide on the CDISC standards required for regulatory submission. |
The SDTM Implementation Guide
Before you begin to map or convert data to SDTM, you should have a basic understanding of how SDTM works. The SDTM Implementation Guide (SDTMIG) is an essential resource to help you with this.
The implementation guide gives a detailed overview of SDTM specifications and metadata for all SDTM domains. It includes guidance for producing SDTM datasets. If you get familiar with the SDTMIG before you start SDTM mapping, it’ll make the whole process much smoother!
Read about 5 common CDISC SDTM implementation challenges and the best practice solutions to each in our free guide.
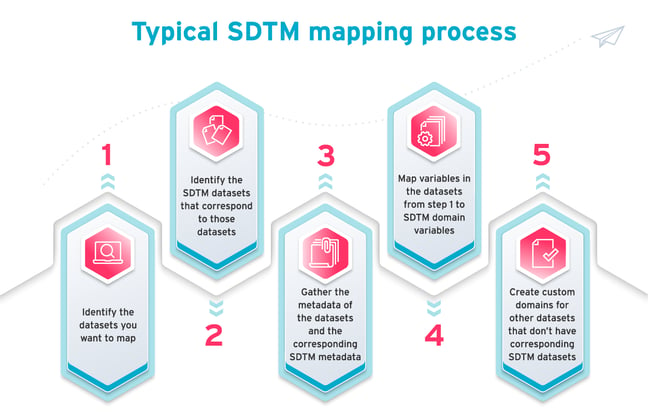
What’s a typical SDTM mapping process?
The SDTM mapping process usually looks like this:
- Identify the datasets you want to map.
- Identify the SDTM datasets that correspond to those datasets.
- Gather the metadata of the datasets and the corresponding SDTM metadata.
- Map variables in the datasets from step one to SDTM domain variables.
- Create custom domains for other datasets that don’t have corresponding SDTM datasets.
Typical mapping scenarios
According to a paper published by PharmaSUG, the mapping itself can involve 9 possible scenarios.
It’s a good idea to become familiar with these scenarios before you begin mapping, so you don’t run into any surprises along the way!
-
The direct carry forward
These are variables that are already SDTM compliant. These can be directly carried forward to the SDTM datasets, and don’t need to be modified.
-
The variable rename
Some variables need to be renamed in order to map to the corresponding SDTM variable. For example, if the original variable is GENDER, it should be renamed SEX to comply with SDTM standards.
-
The variable attribute change
As well as variable names, variable attributes must be mapped. Attributes such as label, type, length, and format must comply with the SDTM attributes.
-
The reformat
The value that is represented doesn’t change, but the format it’s stored in does. For example, converting a SAS date to an ISO 8601 format character string.
-
The combine
In some cases, multiple variables must be combined to form a single SDTM variable.
-
The split
A non-SDTM variable might need to be split into two or more SDTM variables to comply with SDTM standards.
-
The derivation
Some SDTM variables are obtained by deriving a conclusion from data in the non-SDTM dataset. For example, using date of birth and study start date to derive a patient’s age, instead of manually entering the age upfront.
-
The variable value map and new code list application
Some variable values need to be recoded or mapped to match with the values of a corresponding SDTM variable. This mapping is recommended for variables with a code list attached that has non-extensible controlled terminology.
It’s also advisable to map all values in the controlled terminology, rather than just for the values present in the dataset. This would cover values that are not in the dataset currently but may come in during future dataset updates.
-
The horizontal-to-vertical data structure transpose
If the structure of the non-CDISC dataset is completely different from its corresponding SDTM dataset, you may need to transform it to one that is SDTM-compliant. The Vital Signs dataset is a good example. When data is collected in wide form, every test and recorded value is stored in separate variables. As SDTM requires data to be stored in lean form, the dataset must be transposed to have the tests, values, and unit under three variables. If there are variables that cannot be mapped to an SDTM variable, they would go into supplemental qualifiers.

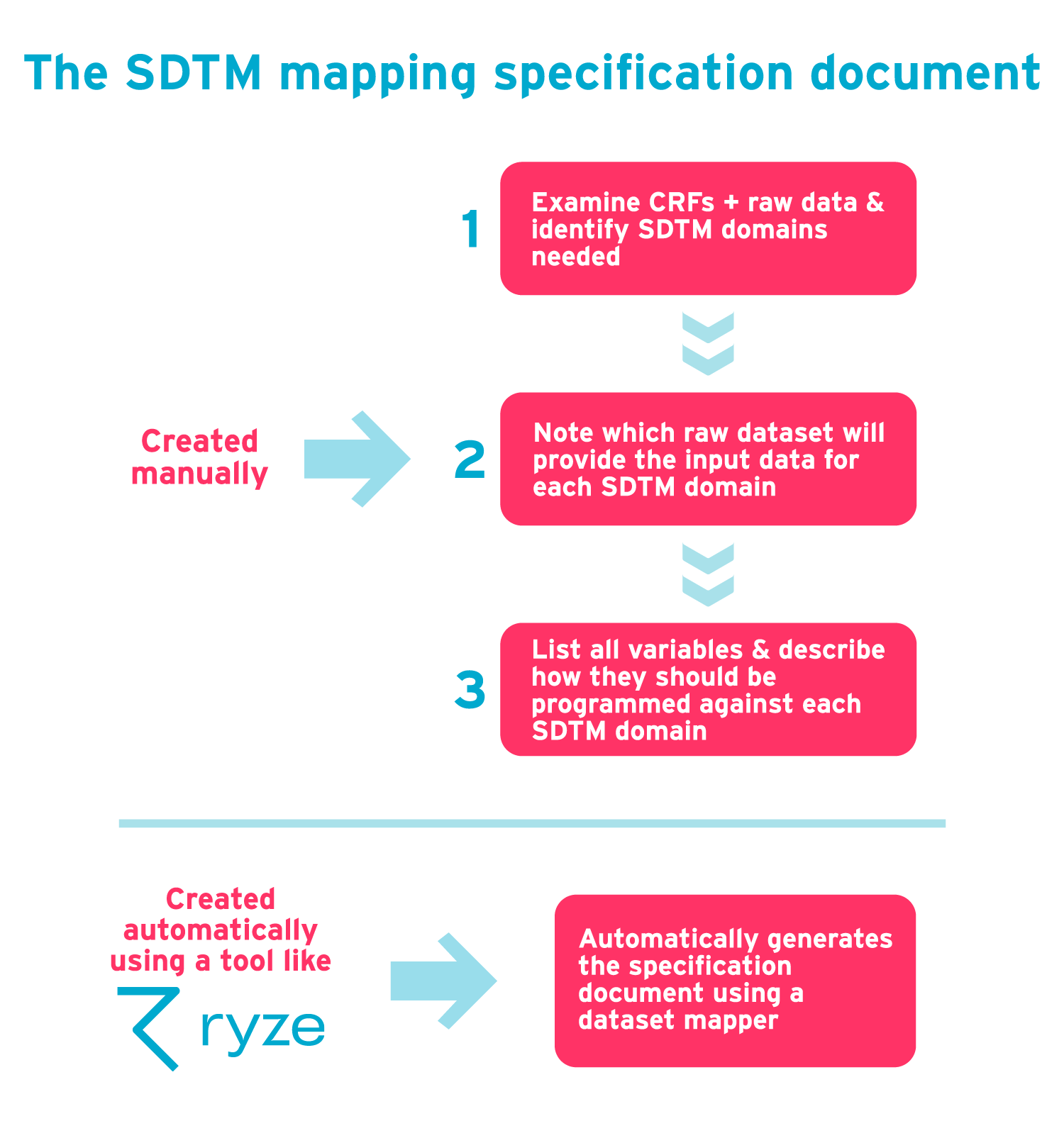
SDTM mapping specification document
The SDTM mapping specification is an important document that’s used when designing the process by which raw data will be converted to SDTM. This document specifies how the raw data is to be converted, and is used by the SDTM programmer and testing team.
It can be created manually as follows:
- Examine the CRFs and raw data and identify which SDTM domains you need.
- Against each SDTM domain, note which raw dataset will provide the input data.
- Against each SDTM domain, list all variables and describe how they are to be programmed.
This manual process can be made easier using a tool like ryze which automatically generates the document from a dataset mapper plug-in. ryze also lets you visualize the specification as you go.
Want your SDTM dataset conversion in one click?
Worried that the raw source datasets from your library or EDC need a lot of work to get them into SDTM format? Or that you don’t have the time or programming skills to do it?
ryze makes it easy to map raw datasets to target datasets. Forget trying to work out what your source dataset headings will be. Our data mapping automation tools help you easily match the variables in SDTM with the relevant variables in your source datasets. There’s no coding involved, and we use templates to speed things up. Once you’re done, your SDTM datasets are just one click away. To put it simply: ryze makes SDTM mapping easy.
Want to find out more? Download our FREE guide to SDTM mapping at the link below.

Author's note: this blog post was originally published in April 2020 and has been updated for accuracy and comprehensiveness.
![]()
About the author

Ed Chappell
Solutions Consultant | Formedix
Ed Chappell has been working as a Solutions Consultant with Formedix for over 15 years, and has 22 years’ experience in data programming. He authored and presents our training courses for SEND, SDTM, Define-XML, ODM-XML, Define-XML and Dataset-XML.
Ed was heavily involved in the development of our ryze dataset mapper, and works closely with customers on SDTM dataset mapping. As an expert in clinical data programming, Ed also supports customers with Interim Analysis (IA) SDTM and FDA SDTM clinical trial submissions.


