Tags:
SDTM

We touched on the SDTM supplemental qualifier in the SDTM mapping process simplified. In this blog, we’ll delve deeper into this subject with detailed examples.
So, what are SDTM supplemental qualifiers? In short, these are variables in non-CDISC datasets that cannot be mapped to a variable that matches the SDTM standard.
What to do with new variables
The Study Data Tabulation Model (SDTM) includes a rule that new variables cannot be added to a data domain. If a user has additional data for a domain which cannot be entered into the domain using the standard SDTM variables, then a supplemental qualifier dataset must be used. This is a separate dataset from the ’parent’ domain in question, and it has a vertical structure that allows the user to add supplemental data in a ’variable name – variable value’ format.
Supplemental qualifiers example
Below is an SDTM+ dataset for DM (Demographics).
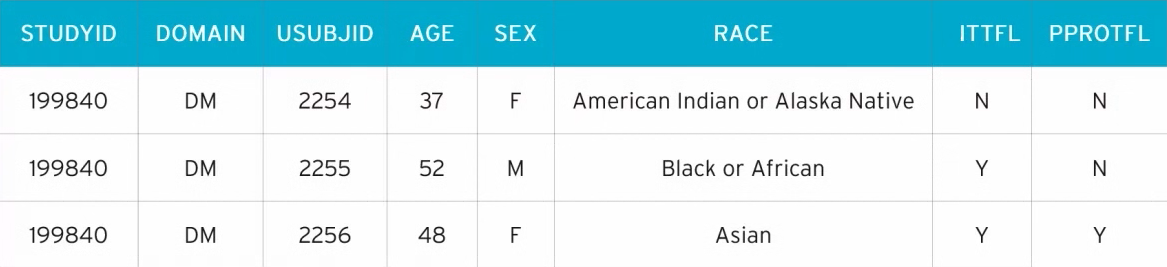
In DM, we have the standard SDTM data:
- STUDYID – the Study ID
- DOMAIN – the dataset domain code
- USUBJID – the unique subject identifier
- AGE, SEX, RACE – the patient’s age, sex and race
In the above example, we also have two variables that aren’t included in the SDTM – ITTFL and PPROTFL. These are the population flags Intent to Treat and Per Protocol.
In this instance, we create a supplemental qualifier dataset, SUPPDM, which is shown below. The naming convention for supplemental qualifier datasets must be adhered to. It will always begin with ’SUPP’ and is followed by two characters that represent the SDTM domain they were created for. So, as in this example, the supplemental qualifier for DM is SUPPDM. Creating a supplemental qualifier dataset for the domain EX (exposure) would result in SUPPEX.
SUPPDM
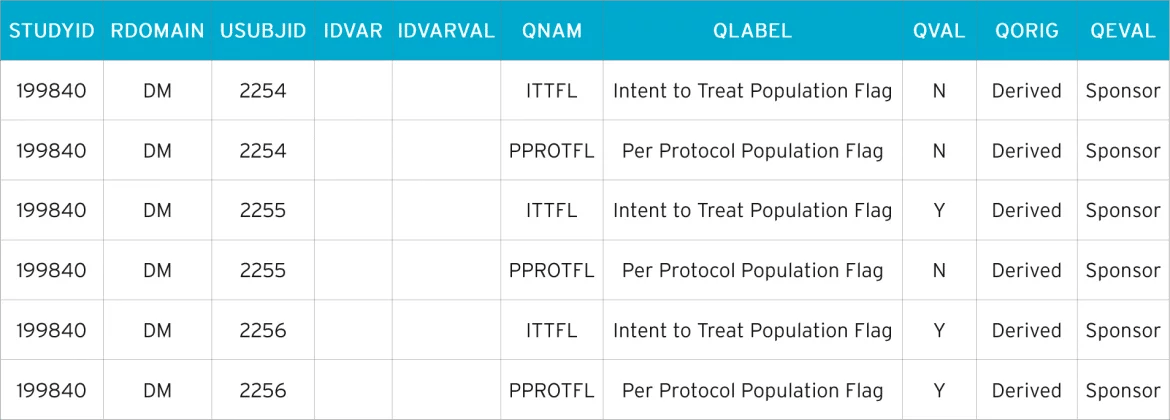
Each supplemental qualifier dataset contains ten variables. Variables in a supplemental qualifier domain are either ’required’ or ’expected’. There are five key variables that reference a specific record in its parent domain and five Q-variables that contain the supplemental data itself.
The key variables are:
- STUDYID –the Study ID
- RDOMAIN – related domain
- USUBJID – the unique subject identifier
- IDVAR – variable which identifies the related records (usually the Sequence variable)
- IDVARVAL – the value of IDVAR (in SUPPDM, IDVAR and IDVARVAL are blank – the SDTM dataset DM contains only one observation per subject and USUBJID is sufficient enough to reference the records)
The supplemental data is:
- QNAM – the variable name
- QLABEL – the variable label
- QVAL – the data value
- QORIG – the origin (CRF/derived, etc)
- QEVAL – the evaluator
Each domain that has non-SDTM standard variables needs a supplemental qualifier dataset. So, if there are 10 datasets that contain non-SDTM standard variables, 10 supplemental qualifier datasets would be created.
What to do about NCI preferred terms for race
The NCI preferred terms for reporting the race of a patient only include American Indian or Alaska Native, Asian, African American, Native Hawaiian or Other Pacific Islander, or White.

So, what happens in a situation where a patient is, for example, Australian Aborigine? The SDTM Implementation Guide answers this question perfectly with the following example.
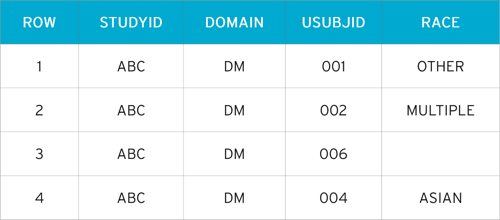
DM - Multiple Race Choices
In this example, the subject is permitted to check all applicable races.

- Row 1 (DM) and Row 1 (SUPPDM): Subject 001 checked ’Other, Specify’ and entered ’Brazilian’ as race
- Row 2 (DM) and Row 2, 3, 4, 5 (SUPPDM): Subject 002 checked 3 races, including an ’Other, Specify’ value. The three values are reported in SUPPDM using QNAM values RACE1 – RACE3. The specified information describing other race is submitted in the same manner as to subject 001
- Row 3 (DM): Subject 003 refused to provide information on race
- Row 4 (DM): Subject 004 checked 'Asian' as their only race
dm.xpt
suppdm.xpt
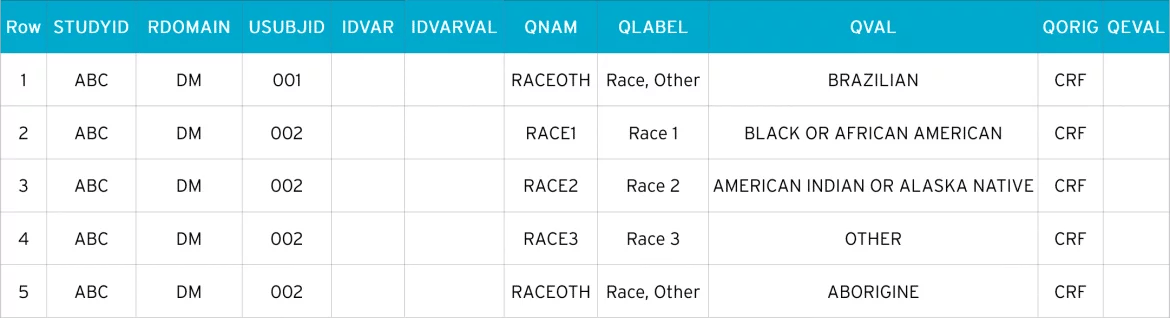
In the SDTM dataset dm.xpt, we see the demographics of Patients 001 – 004.
Here, Patient 001 chose ’Other’. Because his specified race cannot be matched to SDTM, a supplemental qualifier is created where the additional data is stored. So, we can see from suppdm.xpt that the patient has specified ’Brazilian’.
Patient 002 has a much more diverse background. They ticked ’Black or African American’, ’American Indian or Alaska Native’, and ’Other’. And in the ’Other’ field, they have specified ’Aborigine’.
Patient 003 has not answered the question, and Patient 004 has chosen the SDTM-compliant response ’Asian’, so their information is not included in the supplemental qualifier.
Creating SUPPQUAL datasets can be challenging and time-consuming. But, if you have datasets containing variables that cannot be mapped to standard SDTM variables and want to make them SDTM-compliant, it’s completely necessary!
Need help with CDISC SDTM mapping?
Download our free guide to SDTM mapping at the link below.

Author's note: this blog post was originally published in January 2021 and has been updated for accuracy and comprehensiveness.
![]()
About the author

Ed Chappell
Solutions Consultant | Formedix
Ed Chappell has been working as a Solutions Consultant with Formedix for over 15 years, and has 22 years’ experience in data programming. He authored and presents our training courses for SEND, SDTM, Define-XML, ODM-XML, Define-XML and Dataset-XML.
Ed was heavily involved in the development of our ryze dataset mapper, and works closely with customers on SDTM dataset mapping. As an expert in clinical data programming, Ed also supports customers with Interim Analysis (IA) SDTM and FDA SDTM clinical trial submissions.