


Data can come from multiple sources and be stored in different places, systems, and networks. Like edit checks and specifications on spreadsheets. And CRFs and the protocol on PDF documents… the list goes on, and on. And as files are updated, a new version is created. So how do you know if you’ve got the latest version? How do you know if the quality of the data file is good enough? The easiest way is to use a clinical metadata repository!
The only way to keep track of data in different locations is to manage its metadata. And by creating organizational standards that adhere to industry standards, data will be reliable and consistent. You’ll also have greater transparency.
If you’re interested you can read our blog on important aspects to consider before implementing a clinical metadata repository.
What is a clinical metadata repository?
A cloud-based clinical metadata repository is essentially a database that maintains metadata definitions such as forms, datasets, codelists, and variables, throughout the various stages in a clinical trial.
Metadata plays an essential role in allowing different people involved in clinical trials to access, monitor, track, and log data. Being able to manage metadata effectively is a fundamental requirement in clinical trials. This is due to the volume of metadata used over various clinical trials.
 A centralized clinical metadata repository lets teams access information, in a readable format, easily and quickly. It allows for effective planning, communication, and teamwork.
A centralized clinical metadata repository lets teams access information, in a readable format, easily and quickly. It allows for effective planning, communication, and teamwork.
Furthermore, it gives total transparency to all users throughout the process and ensures that data is of a high standard. Both current and historical metadata should be accurate and easily accessible.
A clinical metadata repository is key to effectively managing organizational standards. It lets you:
- Create, maintain, govern and use standards consistently
- Reuse your existing assets
- Realize the impact of changes
- Create accurate mappings
- Be fully compliant
- Create high-quality submissions
The various aspects of MDRs that contribute to data quality are as follows…

Governance process
You can create your own organizational lifecycle for studies and standards. That is, the allowed process that each must go through from start to finish.
Aside from improving data quality, governance lets you control and fully understand the workflow and develop robust organizational standards. This means you can get your product to market more safely and much quicker.
If data isn’t properly managed, it can become out of date and invalid. Good governance means your metadata is accurate and compliant.
Reuse
Organizational standards are stored ‘all in one place’ and can be reused. This includes things like mappings, annotations, controlled terminology, datasets, and so on. A standard can then be updated to suit study-specific requirements. Outputs can also be automated. And because standards have already been approved, tested, and validated, it means data quality is improved and remains consistent.
Impact analysis
One of the key objectives of an MDR is to analyze the impact of a change to metadata -before you make the change. All associated standards and assets will be analyzed to let you know exactly what downstream or upstream metadata and processes will be affected. Impact analysis should also show all assets that are indirectly affected. The diagram below shows how the CRF can be affected by a change in the ADaM dataset.

You can also see how your assets interrelate in the metadata repository.
So the impact analysis tool lets you make an informed decision before you make a change. You know the scope of the updates. And once you have this information, you can decide whether it’s worth making a particular change or not.
Change control
An MDR allows users to set up change requests to existing standard objects. Users should be able to log requests for changes, such as updating a form. The change control process is a pre-defined workflow that defines the approval process and the tracking and handling of change requests. All changes are tracked from inception to completion.
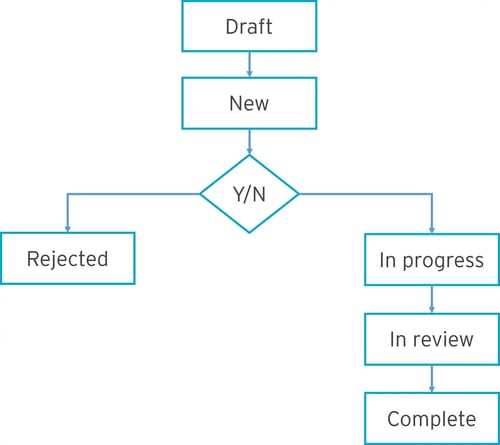
Versioning
A good MDR allows multiple versions of the same standard that have been updated, improved, or customized.
You can easily identify which version of a standard is being used. And users can be confident they’re working on the correct version of an asset or standard.
Traceability
Traceability is of key importance in the world of clinical trials, due to the ever-changing regulatory environment.
Traceability must be built into an MDR so that all assets can be fully tracked through their lifecycle. With traceability in place, you can see who has accessed the MDR. Who made changes to what studies, standards and assets, and when. And you can check the differences between them. For example, the differences between versions of the same standard. You can see the full and detailed history of a standard.
|
Full traceability throughout the lifecycle process ensures audit compliance and increases the chances of a successful submission to the FDA. |
Conclusion
The real measure of data quality comes at submission time. Are many questions raised? And how long does it take to resolve them? If the answer is not long, then you know without a doubt that the quality of your data is high!
Can Formedix help?
Our clinical metadata repository and study automation platform has been built especially for clinical metadata. It’s off the shelf which means you can get started straight away! It covers all the data quality aspects discussed in this blog.
And we’re constantly developing it in line with what’s happening in the industry and with the latest standards and regulations.
If you’re interested in finding out more about clinical trial software, you can read our blog How clinical trial software can be used to optimize clinical trials.
The Formedix platform is used by many pharma companies, biotechs, and CROs. Each organization has its own objectives and processes, and we work with customers to meet their individual needs. Common goals include things like:
- Developing internal standards that can be reused
- Having a central place (MDR) to store forms, datasets, standards and other study data/metadata
- eCRF design (in Rave, InForm, or another EDC)
- EDC specification
- EDC build
- Quickly creating define.xml from SDTM datasets (automate SDTM conversions)
- Getting ADaM datasets into define.xml
- SDTM validation
- Creating Analysis Result Metadata in define.xml
- Automating end to end studies from eCRF through to submission
- Seeing data much faster
- Easier clinical metadata management
Any of these sound familiar?
If so, the chances are we can help. You can request a no-obligation demo to see how our automation platform could work for you. Or arrange a call so we can talk through your situation and go from there.
![]()
About the author

Steven Benham
Professional Services Manager | Formedix
Steven Benham has been with Formedix for over six years. Starting originally as a Solutions Consultant, he worked to author and present Formedix training courses for SEND, SDTM, Define-XML, ODM-XML, Define-XML and Dataset-XML.
He has also been involved in a number of clinical data programming projects helping to deliver in Interim Analysis (IA) SDTM and FDA SDTM clinical submissions. He is now the Professional Services Manager and currently oversees all Formedix clients.


